80% of AI initiatives don’t make it from POC to production. Not because the technology doesn’t work, but because companies attempt to jump from zero to 100% automation in one leap. At aTeam Soft Solutions, we have deployed 20+ AI agents locally in the UAE and Saudi Arabia. There is a pattern to every successful deployment: graduated trust. That’s why an AI agent deployment framework means more than the model, the dashboard, or the very first demo.
The majority of enterprise AI failures aren’t model failures. They’re deployment failures.
The POC works in a conference room. The demo wows the leadership. The group identifies a genuine chance to save time, cut down on manual labor, or enhance compliance. Then the system is rushed early on, makes one visible mistake, and all of a sudden, the whole AI initiative is considered to be high risk.
Slower AI is not the safer road.
The safe route is phased AI development.
An AI agent that is production-grade should not be trusted with all tasks at once. It needs to earn trust in layers. It observes first. Then it recommends something. Then it operates within guardrails. Lastly, it operates on its own autonomously for routine cases while maintaining a full audit trail.
In this article, we explain the 4-phase AI agent deployment framework that aTeam Soft Solutions follows when transitioning enterprise AI agents from POC to production. It is aimed at leaders, CTOs, COOs, CIOs, heads of transformation, and operations teams who want the benefits of automation without risking compliance, cash, or customer trust.
The term “AI agent” is frequently used too casually.
An AI agent is not a chatbot linked to a database. A true enterprise AI agent observes inputs, interprets data, makes decisions, leverages tools, performs workflow steps, escalates exceptions, and maintains logs.
That kind of system gets at real business risk.
If an AI agent sends out a wrong invoice, approves a wrong claim, misses a compliance violation, or updates the wrong ERP record, the cost is not hypothetical. It’s a finance issue, a customer issue, a regulator issue, or a leadership confidence concern.
The majority of failed implementations fall into three patterns.
The Big Bang failure is when a company attempts to roll out full automation on day one.
Leadership sees a great POC and thinks the system is production-ready. Live data and business systems are exposed to the agent, and the agent is given too many permissions too soon. For a while, all seems well.
The agent then commits one error.
It could authorize the wrong invoice. It could deliver the wrong supplier reminders. It could submit a form that is missing a field. It could label a high-risk case as a routine one. The financial consequences could be $5,000, $50,000 or even higher.
Once that kicks in, it’s a different conversation.
The question is no longer “How do we make the agent better?” The question is “Who signed off on this system?”
An AI agent is branded as untrustworthy even if the real cause was bad deployment design.
This mistake happens repeatedly because firms take accuracy in a controlled POC to be reliability in live operations. A POC demonstrates technical feasibility. It does not establish operational trust.
The production AI agent requires staged authority.
The Silence of the Eternal POC is equally destructive but quieter in nature.
The POC functions well. The demonstration is stronger. The team behind the project believes in it. However, no one outlines the route to production.
There’s no decision gate and no accuracy metric. There’s no human review workflow process. There is no security model and no ownership model. There is no integration, rollback, monitoring, or auditing plan.
So it’s still in demo mode.
It might go on for 6 months, 12 months, or 18 months. Eventually, the original champion moves on to another position. The operations department loses interest. The vendor keeps enhancing the demo, but no one really trusts it enough to use it in the real work.
Then the firm says, “The AI did not deliver ROI.”
But the reality is much simpler: the POC never became a rollout.
A POC of an AI agent without the production framework is not a transformation program. It’s an experiment.
The Shadow IT breakdown occurs when a single department creates an AI tool without oversight.
A procurement team might build an agent to distill supplier emails. A finance team can build a tool to extract invoice information. A legal team might use AI to review contracts. The tool works for that team, as the use case is actual and the pain is real.
Then leadership finds out about it.
The initial questions are reasonable:
Who can get the data?
Where are the prompts kept?
Can we audit the decisions we made in the past?
Can we prove why the AI recommended a particular course of action?
Does the system comply with our data protection policy?
Could this scale to other departments?
If there is doubt about the answer, the project is stopped or curtailed.
The Shadow IT failure is not due to bad faith. It is the result of teams addressing genuine pain points more quickly than governance can react.
A good agentic AI implementation approach should allow teams to innovate while protecting the business
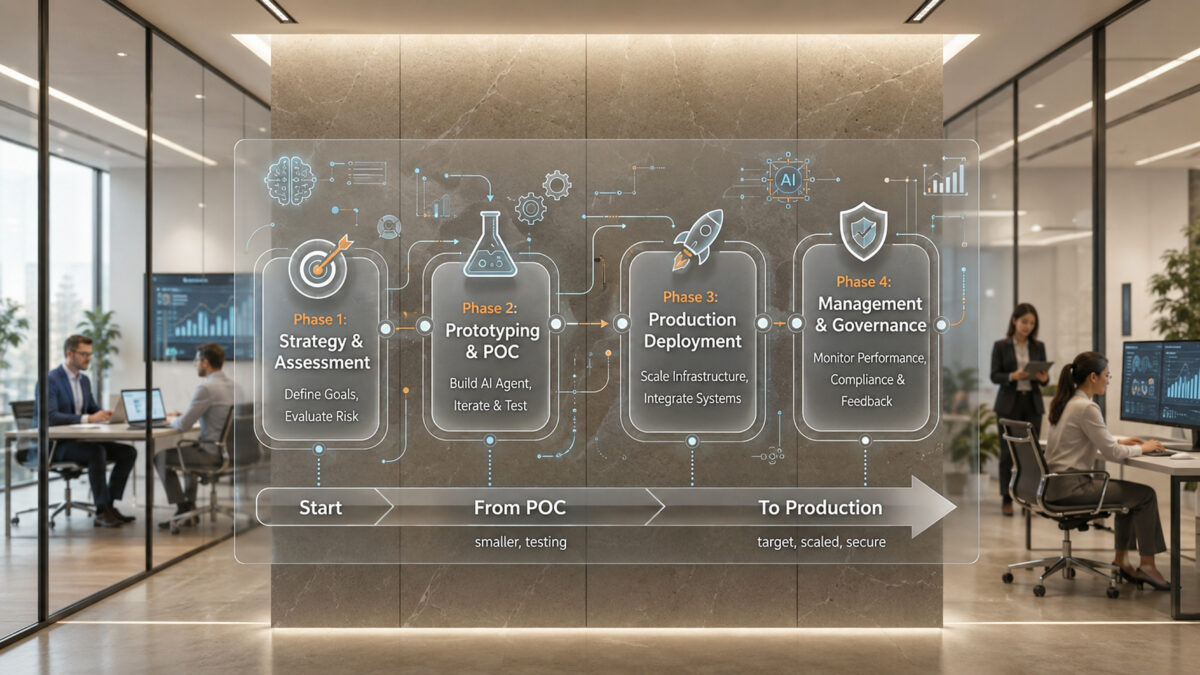
The 4-stage protocol is based on escalating trust.
The agent has no power initially. It just watches and extracts. When accuracy is demonstrated, it recommends actions. When advice is trusted, it operates under guardrails. When performance is steady, it performs routine tasks autonomously under audit and supervision.
The model mitigates risk as the AI gains operational authority gradually.
| Phase | Timeline | AI agent role | Human role | Main decision gate |
| Phase 1 | Weeks 1-4 | Observe and extract data | Review every output | Accuracy above 90% for 2 consecutive weeks |
| Phase 2 | Weeks 5-8 | Suggest actions | Approve or reject suggestions | Acceptance above 95% for 4 consecutive weeks |
| Phase 3 | Weeks 9-16 | Act with guardrails | Handle exceptions | Autonomous error rate below 0.5% for 8 consecutive weeks |
| Phase 4 | Month 5+ | Full autonomy for routine cases | Oversight and audits | Continued performance under audit |
This step-by-step approach is particularly vital for enterprises in the healthcare, logistics, finance, legal, real estate, HR, customs, insurance, manufacturing, and government-linked workflow areas.
These industries can’t allow uncontrolled automation.
They want automation that earns itself.
Phase 1 is simply the AI agent observing the workflow and not taking any action.
The duration of this stage is typically 1-4 weeks, varying with the complexity of the process and the quantity of transactions.
The AI agent observes the data source, retrieves information, structures it, and hands it over to humans for evaluation. It can read the e-mails, PDFs, scanned documents, portal downloads, WhatsApp messages, ERP records, forms, or spreadsheets.
The agent never approves anything.
The agent never submits anything.
The agent never updates the ERP.
The agent does not run downstream workflow jobs.
All it does is watch and take out.
This is the safest way to run the agent on live business data without giving it live business power.
In Phase 1, the AI agent has four main functions to perform.
It watches the source. It can be a mailbox, a vendor portal, a shared folder, a government portal, an ERP export, or a WhatsApp Business API feed.
It extracts information. This can be invoice numbers, purchase order numbers, shipping dates, customer names, tax values, units of measure, document expiry dates, claim IDs, or contract clauses.
It turns unstructured data into structured fields. For example, the agent might convert “shipment expected to leave next Tuesday” into an ETD value in a standard format.
It allows for extracted data to be validated by humans. The output can be delivered in a review dashboard, allowing personnel to accept, correct, or reject the data for each field.
At this point, the ai agent is considered a junior analyst whose output requires full verification.
It is not a weakness. That’s the point.
Every extraction is human-reviewed.
If the agent extracts an invoice amount, a finance user validates that the amount is correct. When an agent finds a ship date, an operations user validates the date. If the agent maps a unit of measure, a procurement user verifies it.
Every fix is a piece of good data.
The team is not just testing the AI. They’re building a human-validated dataset.
This data set serves as a basis for the development of prompts, extraction patterns, validation rules, confidence thresholds, and exception handling.
Phase 1 also gives the company a clearer picture of its own process. Most of the teams often realize in this stage that their manual process is significantly more variable than they expected.
A supplier can have six different date formats. A portal can export different column names according to the applied filter. A hospital can have three different ways of describing the same item. The finance team may have unstated rules, which may be known to senior staff.
Phase 1 reveals the hidden process knowledge as visible.
The key measure is extraction accuracy.
Extraction accuracy, however, should be computed on a per-field basis rather than only at the document level.
An invoice agent can extract the supplier name with 99% accuracy, although tax treatment is 83% accurate. A shipment agent can extract the PO number accurately, yet gets confused by vague ETD terminology. A compliance agent may get most of the risks of invoice rejection right, but miss a few edge cases.
Helpful Phase 1 measurements are the following:
The key deliverable of Phase 1 is a training set of human-validated extractions and a well-defined accuracy benchmark.
For example, the team will be able to say, “The AI extracts unit-of-measurement information with 89% accuracy in week 1, 95% accuracy in week 3, and 98.7% accuracy by month 3.”
That sort of benchmark gives the leadership confidence that they are making measurable progress.
The agent is expected to proceed to Phase 2 only if the accuracy of extraction is above 90% for 2 consecutive weeks.
The threshold may be different depending on the process risk.
90% may be fine for low-risk processes, but for any financial, regulatory, legal, or healthcare process, the bar should be set higher for critical fields.
A customs documentation agent is entitled to a lower degree of accuracy on noncritical descriptive fields, but does not tolerate low accuracy on invoice value, shipment identity, HS code, or consignee details.
Critical and non-critical fields need to be defined separately in the AI agent deployment framework.
In one aTeam Soft Solutions case study, an AI agent was developed to handle Saudi public hospital order information on a governmental procurement portal.
The process included monitoring the portal, extracting orders, downloading CSV and Excel files, reconciling purchase orders, and normalizing units of measure.
The NUPCO portal agent began at 89% accuracy in the 1st week. In week 3, it was 95%. At the third month, the system attains 98.7% accuracy on verified extraction and reconciliation tasks.
The biggest learning was not just that the model got better. The key learning point was that human interventions revealed the true complexity of the operation.
Hospital orders and supplier systems employed different unit conventions. Some entries were labeled in quantities by pack. Other quantities were given in units of each. An entirely automated script would have misprocessed many records.
The Phase 1 review process taught the agent to recognize where the risky mismatches were appearing.
See the related case study: An AI Agent for the Saudi Public Hospital Order Extraction.
If accuracy levels off under 85%, don’t rush forward.
A plateau below the level of 85% can usually be interpreted in one of four ways.
The source data could be too inconsistent. The extraction procedure may be wrong. The procedure may require more validation data. In other words, the agent may require a more specialized architecture.
For example, poor-quality images of scanned documents might require document preprocessing. Supplier messages containing ambiguous language might require conversation history. A compliance workflow could require the addition of structured business rules outside the AI model.
Phase 1 is effective if it identifies these problems in the early stages.
A Phase 1 failure is less costly than a production rollout failure.
Phase 2 starts when the AI agent achieves a level of information extraction reliability good enough to allow it to recommend next actions.
This phase typically lasts from the fifth to the eighth week.
The agent still does not have full autonomy. It proposes actions, and humans accept or deny them.
That’s the phase where human trust begins.
In Phase 1, the staff asks, “Did the AI read this correctly?”
Phase 2, the staff asks, “Is the AI suggesting the right next move?”
That’s a big change.
The agent pulls information and recommends actions.
For example, an invoice agent could recommend: “Make this invoice record and send it for finance approval.”
A supplier ETD agent could say: “Mark this purchase order as late and send a reminder to the supplier.”
A legal document agent may recommend the following: “Raise this clause on account that the indemnity words vary from the approved template.”
A tenant engagement agent may recommend: “Tag this request as emergency maintenance and dispatch the facilities team.”
The AI agent needs to justify its recommendation.
An enterprise AI agent is good not only at saying what needs to be done. It should display the evidence on which the recommendation is needed.
For example: “Flagged because the supplier promised dispatch on 12 April, although the latest message is that dispatch is now the following week.” This applies to PO-1452 and shipment batch B.
It’s this explanation that lets humans approve more quickly.
Humans look at the actions, and one click either approves or rejects them.
Rejections have to be fed back into the system.
A rejection is more than “no.” It’s a learning signal.
The reviewer needs to be able to indicate why the recommendation was incorrect. Is the extracted data incorrect? Is the action too aggressive? Is the business rule outdated? Is the confidence threshold too slow? Does the agent miss the context from another system?
This feedback not only improves the agent but also improves the procedure as a result.
Phase 2 is the change in staff behavior. Users check everything deeply at the beginning. Subsequently, if the agent is good, they begin checking only flagged items and exceptional cases.
That behavioral change is more essential than dashboard accuracy alone.
Trust is not just statistical but is behavioral.
The primary metric is the suggestion acceptance rate.
A high accuracy score on extraction does not imply high quality of action. The agent can parse the document correctly, but proposes the wrong action.
Helpful phase 2 metrics cover the following:
The essential result of Phase 2 is human trust built via demonstrated accuracy.
The staff should start to feel that the agent is alleviating work, not adding more checking work.
When the suggestion adoption rate is over 95% for 4 consecutive weeks, and human reviewers calmly reduce the depth of their reviews, the agent should proceed to phase 3.
The second part is what’s important.
A dashboard might show 96% acceptance, but if staff are still manually rechecking each field with the same intensity as previously, the system hasn’t gained operational trust.
The actual trust is when users start to change their behavior.
They stop scrutinizing every routine item. They now concentrate on exceptions. They take the agent’s explanation as a predefined point. They start to trust the workflow.
That’s the signal that the agent is good to go for controlled execution.
In aTeam Soft Solutions deployment, a supplier ETD tracking agent tracked supplier updates that were received via email, WhatsApp, and WeChat.
The client had more than 60 suppliers and over 200 purchase orders active. The team manually invested a lot of time in chasing shipment updates, interpreting inconsistent messages, and keeping follow-up trackers.
In Phase 2, the AI agent identifies supplier commitments and recommended actions like follow-up reminders, delay flags, and escalation notes.
The acceptance rate of suggestions was 93% in week 1, increasing to 97% in week 6. That enhancement mattered as the workflow relied on disorganized human interaction. Not all suppliers wrote updates in the same way. A few gave the exact dates. Some were more vague in their phrases. A few of them attached the files. Some of them responded in mixed languages.
RPA alone would not have been sufficient as the process needed to be interpreted.
Read the associated case study: Supplier ETD Tracking Agent.
Phase 3 is the stage at which the AI agent begins to operate independently, but only within prescribed limits.
This is the most fragile phase of the entire AI agent deployment framework.
The agent is now allowed to perform automated tasks instead of waiting when its confidence level is high, and the business risk is low, but it still needs to notify the user. It should escalate ambiguous, high-value, high-risk, or policy-sensitive matters to humans.
This is usually the period from the 9th to 16th week.
The objective of Phase 3 is not complete liberty.
The aim is controlled autonomy.
The AI agent performs permitted classes of acts.
An agent for processing invoices might auto-handle invoices for less than $10,000 so long as the purchase order (PO), goods received note, supplier record, and tax details all align.
A tenant service agent can auto-approve routine NOC requests, although NOCs pertaining to visa, legal, or ownership changes will be flagged.
A customs documentation agent may auto-generate document packs when all the needed documents have been collected, but escalate the shipments with missing certificates or value discrepancies.
A recruitment screening agent could perform a shortlisting of candidates that explicitly fit the required skills, but send borderline profiles to human recruiters.
The agent takes action only when its confidence is above a threshold, and the action is within predefined guardrails.
Exceptions are handled by humans.
They monitor the daily summaries, audit a sample of decisions, and modify thresholds accordingly.
The human role changes to supervision from processing.
Rather than review every invoice, the finance user reviews exceptions and performance reports. Rather than chase each supplier update, the operations user checks for cases that are delayed or unclear. Instead of scanning every document line-by-line, the compliance user looks at flagged risks.
This is where we start to see meaningful gains in productivity.
The team doesn’t do transactional work for every case anymore. Instead of that, they are working at the exception level.
Human-in-the-loop design doesn’t mean that humans must approve every single thing. It’s about getting humans to review the right things.
Practical guardrails for this approach include:
A good level of guardrail combines confidence, value, risk, policy, and reversibility.
An early reversible low-value action can be automated early on.
A high-value irreversible action should linger longer under human review.
The primary measure is the quality of processing performed autonomously.
Helpful Phase 3 metrics involve the following:
The agent ought not to be evaluated solely by the number of cases it automates.
It should be evaluated on whether it automates the correct cases and escalates the right exceptions.
A system that is automated for the 90% of cases but leads to serious mistakes is not ready.
A system that automates 65% of cases with almost no serious errors could be production-ready.
The agent should be promoted to phase 4 when its error rate on autonomous actions is below 0.5% for 8 consecutive weeks.
For workflows that carry high risk, the allowable error rate may need to be even smaller.
The threshold should be relative to business impact.
An AI agent that produces internal summaries can afford to make more mistakes than an AI agent that submits tax data, approves supplier payments, or handles healthcare claims.
Phase 3 must not end just because the project timeline dictates it.
Phase 3 should end as the evidence indicates that the agent is ready.
In a single aTeam Soft Solutions implementation, an agent for accounts payable invoices was developed to handle supplier invoices based on the purchase orders and receipt records.
The agent pulled the invoice data, matched it against the ERP information, discovered the exceptions, and forwarded exceptions.
In Stage 3, the AP invoice agent was able to auto-process 72% of invoices without any human agent involvement and maintained an accuracy of 99.2%.
That result was achievable as the agent didn’t attempt to automate every invoice. It automated invoices that passed confidence and rule thresholds. Mismatches, missing PO references, tax issues, duplicate invoices, and high-value cases were escalated.
See the related case study: Accounts Payable Automation Agent.
Phase 4 is not just about “set and forget.”
Phase 4 is “trust, yet verify.”
In this phase, the AI agent manages the entire process on its own autonomously for routine matters. Humans monitor the workflow through exception dashboards, periodic audits, monthly performance reviews, and process improvement sessions.
This stage is generally from the 5th month onwards.
A mature AI agent should act more like a dependable operations layer rather than an invisible black box.
The AI agent handles simple cases end-to-end.
It watches sources, harvests data, verifies information, applies business rules, takes approved actions, updates systems, notifies, escalates exceptions, and logs every decision.
The agent must still work within a defined set of policies.
Full autonomy does not imply full power.
A compliance agent can run autonomously for normal invoice audits while escalating on suspicious tax patterns. A healthcare claims agent may auto-generate pre-authorization submissions and require them to be reviewed for high-value or denied cases. A legal agent may sum up the contracts; however, they may not approve non-standard indemnity provisions without human review.
Scope for autonomy is a risk.
Humans maintain the strategic control.
They evaluate the exception dashboards. They examine the review samples. They track performance drift. They modify business rules. They find new automation opportunities. They examine user complaints and edge cases.
The human element moves to process governance.
That’s the right end state.
The AI agent takes care of the routine work. Humans are responsible for decisions, improvements, and accountability.
A production AI agent has to keep four layers of control.
Firstly, it requires an entire audit log of every decision. The company should be able to know what data the agent read, what it extracted, what recommended action was taken, what confidence score it assigned, and if a human evaluated it.
Secondly, the system must have rollback capability. If the agent makes a wrong update on a record, the team should be able to reverse the action promptly.
Thirdly, it requires ongoing monitoring of accuracy. Accuracy may drift as suppliers change formats, regulations change, business rules change, or source systems change.
Fourth, its performance should be reviewed monthly. AI agents need to be treated as operational systems, not as one-time software rollouts.
For one, in aTeam Soft Solutions deployment, a ZATCA compliance agent was created that monitors invoices before submission and looks for possible rejection risks.
Before submission, the agent also verified the invoice patterns, validation errors, fields omitted, and compliance risks.
In Phase 4, the ZATCA compliance agent was operating autonomously for daily checks and had identified 97% of possible rejections before submission. An ongoing monthly review assured continued accuracy and also allowed rules to be refined as patterns changed.
This is the correct model for a regulated workflow process.
The agent operates constantly, but there are still humans who monitor its performance.
See also the related case study: ZATCA Compliance Monitor Agent.
Executives usually have an understandable question: “Why can’t we just skip Phase 1 and Phase 2 and start automation?”
The answer is no for any process that involves financial, regulatory, customer, legal, or operational risk.
Omitting phases takes away the proof necessary to have faith in the system.
Without a Phase 1, the business has no way of knowing if the AI agent is even capable of accurately interpreting real-world data.
Without phase 2, the company doesn’t know if the AI agent picks the right action.
Without phase 3, the company does not know if the AI agent can be safely executed in a controlled environment.
Complete automation without such steps is not speed. It is the exposure.
A non-A-team example demonstrates the risk plainly. A finance team rolled out an AI-enabled invoice approval tool straight from a successful POC into a live operations environment. The POC dataset consisted of clean invoices from regular suppliers. Production invoices contained partial shipments, tax corrections, duplicate supplier references, and credit notes.
The agent cleared multiple invoices that had to be flagged for evaluation. One duplicate payment exceeded $50,000 before the problem was detected. The leaders ended the project, not because the AI could not solve the problem, but because the implementation bypassed validation and guardrails.
A staged rollout would’ve caught the problem early on.
During Phase 1, duplicate invoice patterns would have shown up as exceptions in extraction and matching.
During Phase 2, reviewers are expected to reject false approval proposals and produce feedback data.
During Phase 3, duplicate payment risk would be placed under a guardrail that requires human approval.
The issue was not that AI was incapable of handling invoices.
The issue was that autonomy was given before trust was earned.
An AI agent phased rollout protects the company from this very mistake.
The timeframe is determined by the complexity of the process.
A straightforward workflow involving one data source and structured data can get to production in 8-12 weeks.
A medium workflow with multiple sources and semi-structured data can take 14 to 20 weeks.
A complex workflow involving unstructured data, regulatory constraints, multilingual input, and multiple integrations can take from 20 to 32 weeks.
The objective is not to increase the timeline. The objective is to make manufacturing safer.
| Process type | Example | Data complexity | Integration complexity | Typical timeline |
| Simple | Structured report extraction from one internal system | Low | Low | 8-12 weeks |
| Medium | Supplier ETD tracking from email and WhatsApp | Medium | Medium | 14-20 weeks |
| Complex | Invoice compliance, customs documentation, healthcare claims | High | High | 20-32 weeks |
| Regulated enterprise workflow | ZATCA, insurance, legal, healthcare, customs | High | High | 24-32 weeks |
A straightforward process has a single main data source, known inputs, minimal exception volume, and low risk to downstream processes.
Examples involve monitoring internal reports, processing structured forms, or harvesting data from a stable system.
Even for straightforward processes, a phased methodology remains helpful. The phases can be shorter, but they cannot vanish.
A medium process is characterized by multiple sources, semi-structured data, and an average level of exception handling.
Supplier follow-up tracking processes, HR documentation collection, real estate service requests, and customer support classification are often of this category.
These processes typically require sufficient time for the AI agent to learn patterns from real human evaluation.
An elaborate process, such as unstructured documents, various integrations, risk of compliance, multilingual information, and costly exceptions.
Areas such as customs documents, ZATCA invoice tracking, insurance claims, healthcare pre-authorization, legal document analysis, and financial approval processes fall into this category.
These are deployments that require stronger testing, stronger guardrails, stronger audit logs, and more careful decision gates.
For sophisticated processes, 20–32 weeks is not slow. It’s reasonable.
A rushed execution that fails after release is more costly than a phased execution that navigates to steady production.
A lot of teams get a POC confused with Phase 1.
They aren’t the same.
A POC demonstrates that the AI agent can rectify the problem in principle. Phase 1 demonstrates that the AI agent can process the company’s actual data in a controlled production environment.
| Area | POC | Phase 1 |
| Purpose | Prove feasibility | Prove live extraction reliability |
| Data used | Sample or selected data | Real operational data |
| Environment | Controlled | Production-adjacent |
| Human review | Demo-level review | Every output reviewed |
| Main output | Confidence to continue | Accuracy benchmark and validated dataset |
| Risk level | Low | Low to medium |
| Decision value | Should we build this? | Is this ready to suggest actions? |
A POC is just a prototype.
Phase 1 is the initial stage of production deployment.
That distinction matters, since a lot of AI projects go wrong by considering a strong POC as if it were a production-grade system.
The most reliable method for introducing AI agents in an enterprise is via graduated trust.
Don’t switch from POC to full autonomy in a single jump.
Use Phase 1 to demonstrate extraction quality. Use Phase 2 to demonstrate the quality of the recommendations. Use Phase 3 to demonstrate controlled autonomous operation. Use Phase 4 to process routine cases with audit trails, supervision, and ongoing monitoring.
This AI agent deployment methodology enables companies to mitigate the risk of Big Bang failures, Eternal POCs, and Shadow IT.
And it provides leadership with a concrete set of things to manage: accuracy rates, acceptance rates, autonomous processing rates, error rates, exception volumes, and audit outcomes.
aTeam Soft Solutions follows this phased delivery approach as enterprise AI requires more than a working demo. It requires trust to operate.
If your organization is considering an AI agent for finance, logistics, healthcare, legal, customs, HR, real estate, retail, or compliance procedures, begin by asking a single question:
“What kind of trust has this agent actually accumulated?”
This answer will determine the amount of power that the agent has.
That is the way for AI agents to go from POC to production without unnecessary risk.
Deploying an AI agent from POC to production typically takes 8 to 32 weeks, but it depends on process complexity.
A simple flow with a single structured data source takes approximately 8 to 12 weeks. A medium workflow with a number of sources and semi-structured data could run 14 – 20 weeks. A complicated, regulated workflow process with unstructured documents, multiple integrations, and human approvals could take 20 to 32 weeks.
The timeline should be driven by risk, instead of excitement.
AI agents may be launched without a human-in-the-loop stage, but only for low-risk processes with errors that are inexpensive, reversible, and easily detectable.
In financial, regulatory, legal, healthcare, customs, HR, or customer-facing workflows, omitting human-in-the-loop review is a risk.
The human-in-the-loop phase allows the company to verify accuracy, establish trust, gather feedback, establish guardrails, and prevent early mistakes from becoming failures that lose leadership.
In Phase 3, the AI agent should run with guardrails, audit logs, confidence thresholds, and rollback functionality.
If the agent makes errors, the system should record the event, recognize the source data, display the decision path, enable rollback if feasible, and route similar cases in the future to human review.
A Phase 3 error has to enhance the system. It should not result in uncontrolled destruction.
That’s why phase 3 takes place before complete autonomy.
An AI agent is deemed ready for autonomous execution once it satisfies defined thresholds for accuracy, acceptance, error, and exceptions for a specified period.
A realistic target is for the extraction accuracy to be greater than 90% for 2 consecutive weeks, the suggestion acceptance rate to be greater than 95% for 4 consecutive weeks, and the autonomous error rate to be less than 0.5% for 8 consecutive weeks.
The exact threshold should depend on the business risk.
The margin for error is higher in a low-risk support process than in a tax, healthcare, legal, or payment process.
A POC shows that the AI agent can function in principle. Phase 1 demonstrates that the AI agent is capable of functioning on real-world data, but under a tightly managed oversight.
A POC typically operates on sample data in a controlled demo environment. Phase 1 operates on live or production-similar data, human reviewers check every output, and establish a validated accuracy baseline.
A POC responds, “Is this possible?”
Phase 1 responds, “Is it good enough to go on towards production?”
The most safest way is to enhance the agent’s privilege in phases.
Begin by observing and extracting. Switch to propose and agree. Then, enable the agent to act with guardrails. Finally, enable complete autonomy, but only for routine cases, with audit trails and continuous monitoring.
This method minimizes the operational risk as the AI agent is trusted prior to being given authority.


