
Collaborating with Indian development teams has huge advantages—access to world-class talent, cost efficiency, and the promise of working almost 24 hours a day due to the follow-the-sun model of operations. But the 9.5-14 hour time difference between India and the U.S., and the 4.5-6.5 hour difference between Europe and India, can pose collaboration problems that may negate these benefits if they’re not addressed strategically.
This playbook is a collection of proven frameworks to help you get the most out of collaborating across time zones. Whether you’re a startup founder working with a small offshore team or an enterprise CTO overseeing distributed development at scale, you’ll discover actionable strategies to guide you through overlap patterns, asynchronous communication rituals, decision documentation, escalation protocols, and meeting templates—all designed to transform time zone differences from obstacle to advantage.
The India Standard Time (IST, UTC+5:30) results in very large time differences with the main centres of business in the world:
Time differences in the United States depend greatly on location. The US East Coast (EST/EDT) is 9.5-10.5 hours behind India, so when it is 9 AM Monday in New York, it is 6:30-7:30 PM Monday night in India. The US West Coast (PST/PDT) is even further behind, 12.5-13.5 hours behind India—when it’s 8 AM Monday morning in San Francisco, Indian programmers are still burning the midnight oil at 9:30 PM Monday night.
The Central US time (CST/CDT) and Mountain (MST/MDT) time zones are in between at 10.5-11.5 and 11.5-12.5 hours behind, respectively.
European time differences are much more manageable. The time is 04:30 in London, when the time is 07:00 in India, but the United Kingdom and Ireland (GMT/BST) are 4.5-5.5 hours behind India while Central Europe (CET/CEST) is 3.5-4.5 hours behind. London begins its workday at 09:00 am, which is equivalent to 01:30 – 02:30 pm in India, providing good overlap with the Indian workday (standard hours).
Daylight Saving Time also gets complicated because of the complications around DST. From the second Sunday in March until the first Sunday in November, the US is on DST time, and the time difference is an hour less during that time. India does not do DST, so twice a year, the overlap windows shift for teams in the US.
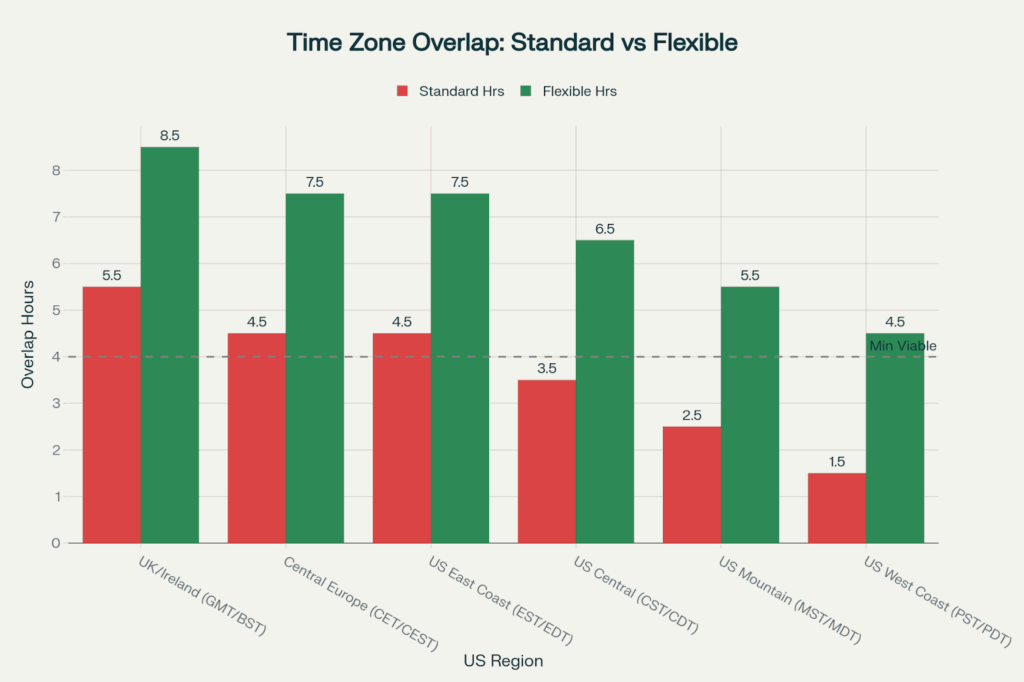
This chart shows how staggered schedules dramatically increase collaboration windows with teams on the US East Coast, now enjoying 7.5 hours of overlap compared to 4.5 hours with inflexible schedules.
With both ends working 9 am-6 pm as a day to both sides, only being for US teams:
On the US East Coast, the duration of overlap is about 4.5 hours when Indian developers work 9 AM-6 PM IST (16:30 – 01:30 EST). This means that Indian developers either have to stay back till 9-10 PM IST for their US meetings in the afternoon, or US teams need to get together before 9 AM EST—neither of which is feasible long-term.
The challenge for US West Coast teams is even more pronounced with a mere 1.5 hours of overlap during “normal” workdays, meaning one party has to burn the midnight oil to collaborate in real time.
UK teams, under the European umbrella, share 5.5 hours (1:30 PM-6 PM IST = 9 AM-1:30 PM GMT) & Central Europe 4.5 hours. This natural advantage makes working between Europe and India much easier than between the US and India.
However, flexible scheduling turns these restrictions into flexibility. With Indian developers moving to 7 am-8 pm flexible hours and US teams opting for early or nighttime meetings, these working hours overlap can grow to as much as 7.5 hours for US East Coast, 6.5 hours for US Central, and 4.5 hours even for US West Coast teams.
Rather, the question is not if there should be overlapping time, but rather how to design workflows that optimize for productive asynchronous time and use your limited synchronous time for the few things that really require real-time interaction.
Traditional, meeting-centric collaboration expires in the face of multiple clocks. Studies suggest that the typical technologist spends 14 hours a week in meetings — that’s the equivalent of 80 days a year — and wants 20 hours a week for deep work, but only gets 11. Add time zone differences on top of meeting overload, and it’s a recipe for disaster for both productivity and quality of life.
Several forms of the meeting trap emerge when you are operating in India-US time zones:
Exhaustion from odd hours: Indian developers are pushed to burn the midnight oil working 9 PM-1 AM IST for US afternoon meetings, or the US teams are called upon to meet at 6-7 AM for Indian business hours, in both cases creating an endless drain that pushes the best talent away. 38% of US businesses say they face significant challenges due to reduced overlapping hours with Indian teams and cited time zone differences as hampering real-time collaboration, even with an advantage on cost.
Deep work is killed by fragmented calendars: Flow state is interrupted by meetings scheduled throughout the day, inhibiting the extended focus required to handle complex coding, architectural design, and problem-solving. Webinars and conference calls scheduled for distant time zones frequently take place at inconvenient hours, dividing productive time into a bunch of nonproductive intervals.
Scalability constraints: Synchronous communication doesn’t scale — all of a sudden, everyone needs to be in every meeting, burning out colleagues. As teams grow from 5 to 15 to 50 people, spread across time zones, meeting-based coordination becomes impossible.
Silos of knowledge: Important information that’s only shared in meetings becomes stuck in people’s heads, creating single points of failure and leaving team members in other time zones out of the loop. When decisions that affect the team are made synchronously with no documentation, distributed teams are burdened with chronic information holes.
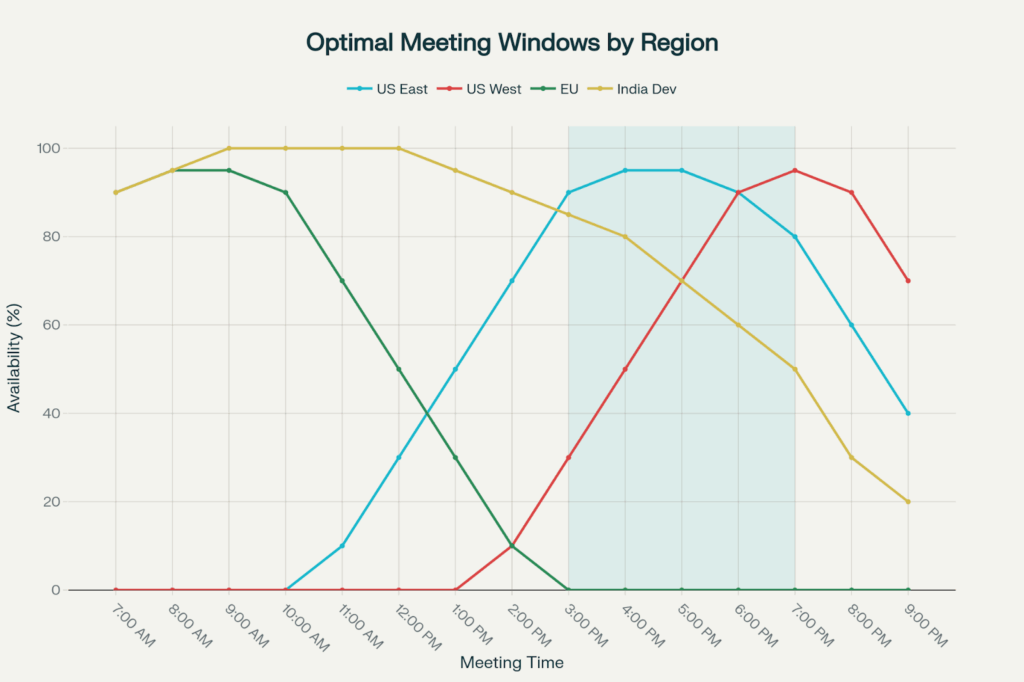
This visualization shows the ideal meeting times for various time zones, with 3-6 PM IST being the best US hours for collaboration with a decent level of comfort for Indian developers.
Async-first collaboration is a way of working that places more value on asynchronous communication than synchronous interaction, with three pillars:
Meetings are a last resort, not the first course of action. When considering whether or not to meet, consider if the goals can be met via written documentation, recorded video, collaborative documents, or already established asynchronous communication (chat). Save synchronous time for when you really need to talk in real time: important decisions with subtle tradeoffs, big architectural debates, or delicate human issues.
Writing is the main channel of communication. Distributed teams operate through written artifacts—tech spec, architecture decision records, status updates in project management tools, and comprehensive documentation. Writing clarifies thinking, creates referable knowledge, and allows us to consume at each person’s optimal time.
It’s normal and necessary to have some reasonable communication lags. In async-first environments, 4-8 hour response times (for non-urgent questions) are considered standard and not stress-inducing. This kind of acceptance removes the necessity of being “always on” and permits real flexibility in one’s workday.
Research and hands-on experience provide strong benefits for an async-first distributed team:
Work-life balance & location flexibility: Collaboration is asynchronous so work is conducted at hours convenient to the individual’s personal life, and eyes don’t need to be synced to arbitrary synchronous schedules Well Indian developers can now decide if they want to start work at 7 AM to have maximum overlap with the US or the standard 9 AM-6 PM work day, based on their preferences. US team members may begin at 10 a.m. after escorting their children to school or leave at 3 p.m. for morning commitments.
Diversity and inclusion: Synchronous meetings discriminate against introverts, non-native English speakers, and neurodivergent individuals who do best with time to develop thoughtful answers. Async communication also levels this playing field, allowing all to submit their most thoughtful insights irrespective of verbal fluency or reaction speed. The ability to participate from multiple time zones also makes it possible for caregivers, persons with disabilities, and anyone else whose life situation may not allow for participating in traditional real-time work to be a part of the community.
More effective onboarding and knowledge sharing : Async-first teams generate a wealth of written documentation as a by-product of communication. This collection of wikis, decision records, specifications, and threaded discussions becomes critical for getting new team members up to speed and for preserving knowledge as people move on. New employees get answers to 80% of their questions on their own via searchable documentation instead of interrupting coworkers.
A scalable medium of communication: Reading is 3-4 times faster than listening. Written artifacts can be read by 5, 50, or 500 people with equal effort, while each additional participant in a meeting adds their time in kind for a synchronous meeting. Written communication that can be referenced later allows teams to grow without causing communication overhead to grow at the same rate.
Deep work and flow states: Removing needless meetings results in large chunks of uninterrupted time, which is necessary for high-level thinking and problem-solving. Developers report becoming 40 to 60 percent more productive when they move from fragmented, meeting-heavy schedules to async-first workflows that feature 4 to 6-hour blocks of deep work.
Bias for action: Async cultures embrace the “make the best decision you can with the information you have, document it” mentality, rather than waiting for synchronous rundowns or approval meetings. This results in much faster execution, while ensuring quality through transparent decision logs that allow course correction, if necessary.
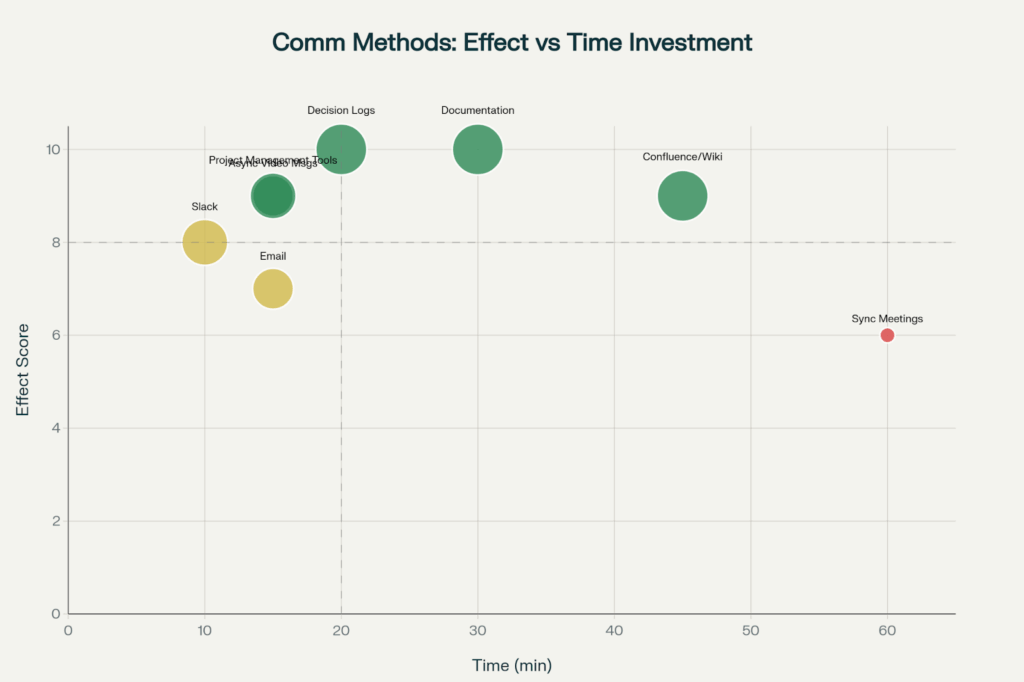
This scatterplot determines the best communication channel for a distributed team, where written documentation and decision logs are the most effective with a reasonable amount of time investment.
Although an async-first approach eliminates dependence on synchronous communication, strategic overlap scheduling takes advantage of the scarce real-time slots.
Flexibility is routine for Indian developers, who can easily shift their workday to achieve greater overlap without undue hardship. Rather than work with strict 9 AM-6 PM schedules, set core hours (10 AM-4 PM IST) during which everyone must be available, and allow for early begins (7 AM) or late ends (8 PM).
This rather comfortable 7 AM-8 PM window gives you 7.5 hours potential overlap with the US East Coast (9:30 PM IST-5 AM IST = 11 AM-7:30 PM EST) and 4.5 hours potential overlap with the US West Coast (9:30 PM IST-2 AM IST = 8:30 AM-5 PM PST). Most developers who don’t have to work daily are happy to adjust to an early or late schedule and be paid for it.
Flexibility in the Indian team is well complemented by the US team’s ability to accommodate early and late meetings. The US East Coast teams’ sprint planning at 8:30 AM EST (6 PM IST) or daily standups at 7 AM EST (4:30 PM IST) allows natural Indian contribution at their normal working hours. West Coast teams embracing 7-8 AM PST meetings (7:30-8:30 PM IST) similarly unlock overlap.
Rotating sacrifice evenly spreads uncomfortable hours rather than having one side always bearing the brunt. Week 1, the Indian team stays through 9 PM IST for 10:30 AM EST meetings. Week 2, US team at 7 AM EST for 4:30 PM IST talks. This rotation avoids burnout and allows for regular synchronous touchpoints.
The scheduling optimality of peak overlap time is that activities of the highest value with the greatest need for interactivity are scheduled during peak overlap times. For the teams on the US East Coast + India team: 3-6 PM IST (5:30-9 AM EST) is the best timing that Indian developers can work comfortably in the early morning, and US teams could meet late at night. Schedule sprint planning, architecture discussions, and critical stakeholder meetings for this window.
Utilize this decision framework to perform synchronous events:
For the US East Coast + India cooperation:
For the US West Coast + India cooperation:
For the Europe + India cooperation:
For worldwide teams (United States + Europe + India):
Success with async collaboration starts with developing explicit rituals that replace syncing and keep the team connected.
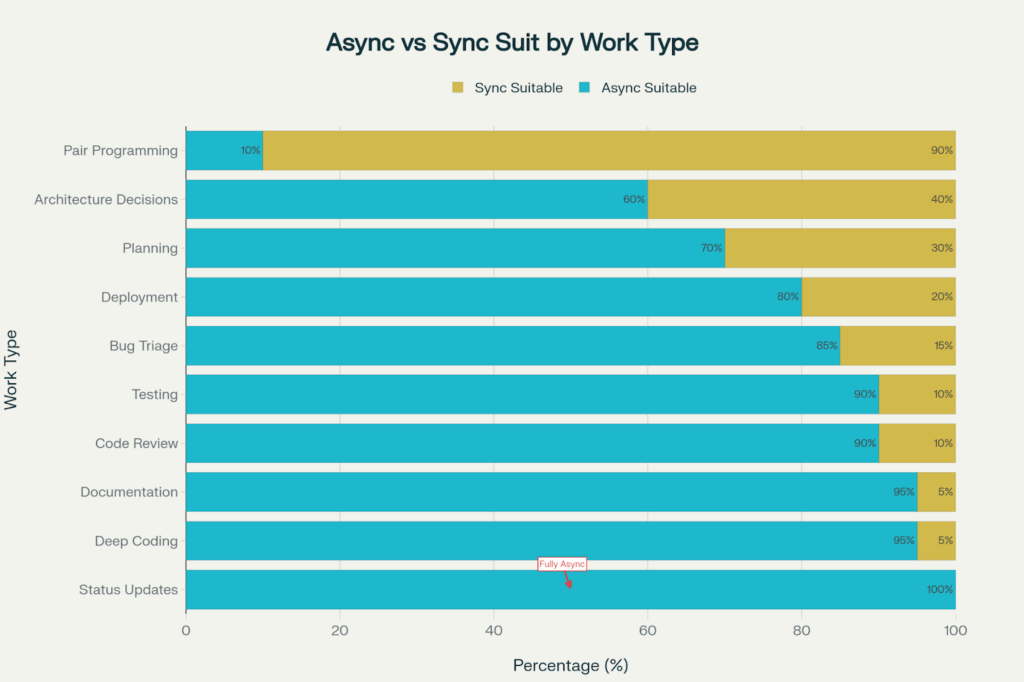
This breakdown highlights that 80% of the development process could be executed asynchronously and that only pair programming demands real-time collaboration.
Switch synchronous daily standups for written updates shared on a specific Slack channel or Confluence page:
Format & timing: All team members submit an update within 2 hours of starting work – Indian team by 11 AM IST, US team by 11 AM EST/PST. Structure should be used consistently:
text
Yesterday: [Completed work, merged PRs, resolved issues]
Today: [Planned work, in-progress items, focus areas]
Blockers: [Impediments requiring help or decisions]
Questions: [@mentions for specific people who can help]
Response timeline: TMs read updates asynchronously and respond to questions/blockers within 4 hours. Project leads synthesize patterns and escalate systemic impacts. This is a bit like having synchronous standups for visibility, but you do not need to have everyone online at the same time.
Alternative to video standup: For teams who treasure richer communication, record 2-3 minute video standups (using Loom) and post to Slack/Confluence. Videos communicate the tone and nuance that text intrinsically lacks while still allowing for asynchronous consumption. Indian team records before EOD; US team watches the next morning and vice versa.
Turn your synchronous demo meetings into a self-paced showcase week:
Monday: Developers record 5-10 minute Loom videos showing off finished features, explaining technical approaches, and what work is left. The videos are posted on a shared Confluence page (organized by epic/feature).
Tuesday-Thursday: Stakeholders view demos at their leisure and leave timestamped comments/questions inline on the video. Product managers distill feedback into structured documents.
Friday: 30-minute live Q&A session , optional during overlap hours to discuss complicated questions that were raised in async review. Most straightforward feedback is handled without synchronous time.”
This pattern shortens the 90-minute synchronous meeting to 30 minutes, while tightening the review—stakeholders can stop, rewind, and reflect, rather than trying to listen up, process in real time.
The most important async ritual in follow-the-sun operations is a thorough end-of-day handoff:
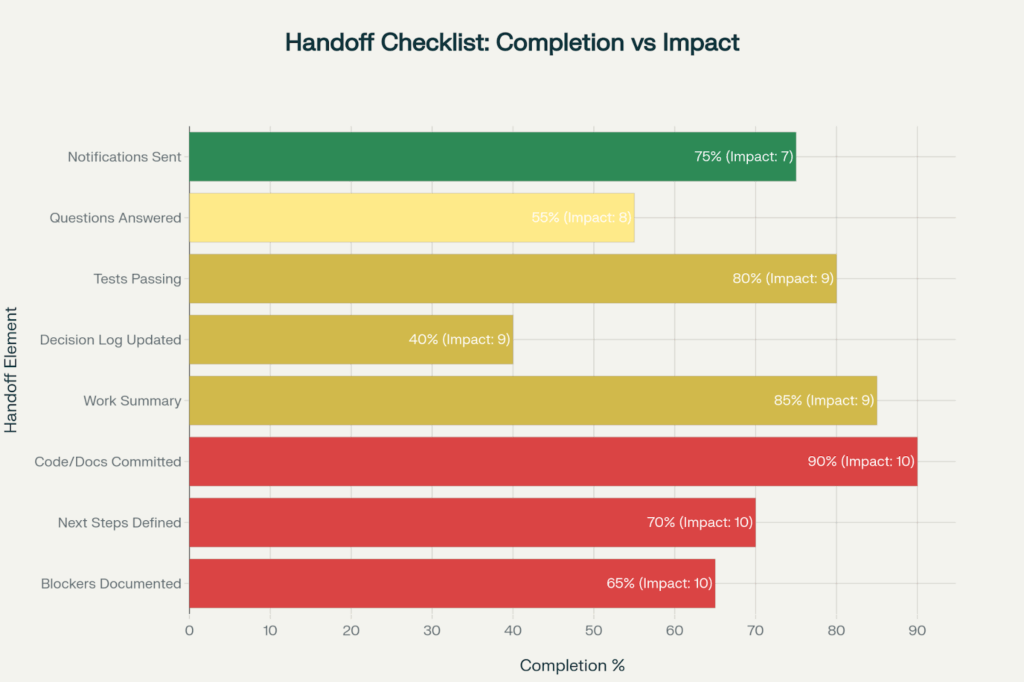
This chart reveals significant handoff issues, as the decision log updates (40% completion) and answered questions (55%) are lagging behind, while they have the biggest impact on the productivity of the team.
Template structure for handoffs:
Work Summary (10 minutes):
Blockers and Impediments (5 minutes):
Next Steps and Priorities (7 minutes):
Questions and Context (8 minutes):
Code and Documentation Status (5 minutes):
Test and Environment Status (3 minutes):
Decisions Made (5 minutes):
Communication Summary (2 minutes):
Full handoff time: 45 minutes of structured documentation saves hours of interruptions and confusion. Post handoffs to a dedicated Confluence space and notify the next shift via Slack.
Research indicates that teams with disciplined handoff routines resolve issues 40% faster and have 60% less duplicated work than those with informal handoffs.
Make use of project management tools to avoid manual status reporting:
Jira automation: Set a daily automatic digest of tickets moved to In Progress, In Review, and Done in the last 24 hours. These updates flow to Slack channels automatically, but without human intervention.
GitHub/GitLab integration: Set commit notifications, PR summaries, and deployment status notifications to be sent to team channels. This provides a passive awareness of progress with no meetings or manual status reports.”
Confluence page updates: Add macros to generate status pages with information about the current sprint progress, velocity trends, and blocker overviews extracted from Jira. Stakeholders can get the current status at any time, without interrupting developers.”
Dashboard visibility: Real-time dashboards (Grafana, Datadog, custom tooling) that provide visibility into build status, test results, deployment health, and application performance metrics. Centralized visibility replaces status update meetings.
Decision logs are the most valuable mechanism for coordinating among distributed teams, and yet less than 40% of teams actually keep them regularly.
Distributed teams also suffer from “decision amnesia” — the initial reasons for decisions get lost to time, and expensive rework results as conditions shift. A decision log establishes the single source of truth that can stop infinite discussions and let new people on the team know the “why” behind the current architecture.
Example situation: Six months ago, your team chose MongoDB over PostgreSQL for storing user profiles due to a lack of time and schema uncertainty. But now performance issues are reported and team members not present start pushing to change databases. When you don’t have a decision log, you spend hours trying to reconstruct the original thinking. A log lets you know immediately that the decision was temporary, based on certain time constraints, and that it is an explicit subject for future re-evaluation.
Apply this full template to all major technical and product decisions:
Decision ID and Metadata:
Decision Statement:
Context and Background:
Decision Maker(s):
Alternatives Considered:
Rationale and Justification:
Decision Impact and Consequences:
Implementation Actions:
Follow-Up and Review:
Document the Spend Decision as soon as the right decision is made. Do not write it days after. Reasoning becomes less clear in 24h. Designate someone in each meeting to write the decision log item before the meeting finishes or shortly after.
Link decisions bidirectionally. When Decision B is dependent on or conflicts with Decision A, link them together. This produces a web of context that prevents decisions from becoming isolated and at odds.
Leverage decision logs as part of your onboarding. New teammates should read decision logs in chronological order within their domain to learn how the architecture they are working with came to be and why certain alternatives were dismissed.
Scan the decisions log quarterly. Things change—what made sense six months ago may not right now. Reviews are scheduled in order to prevent decisions from solidifying into dogma when context changes.
Don’t record every single decision. Prioritize decisions that will have a lasting impact, such as architectural decisions, technology choices, API designs, major refactors, and feature prioritisation. Individual ticket implementations do not deserve formal logs.
Ensure logs are Searchable and Accessible. Save in a Confluence page or in a GitHub repository, or wiki, with tags and by categories. When folks cannot locate the decisions that affect them, logs are worth nothing.
Well-defined escalation paths become even more important when teams are spread across time zones—what is an emergency that should wake someone up at 2 AM, and what can wait until the next business day?
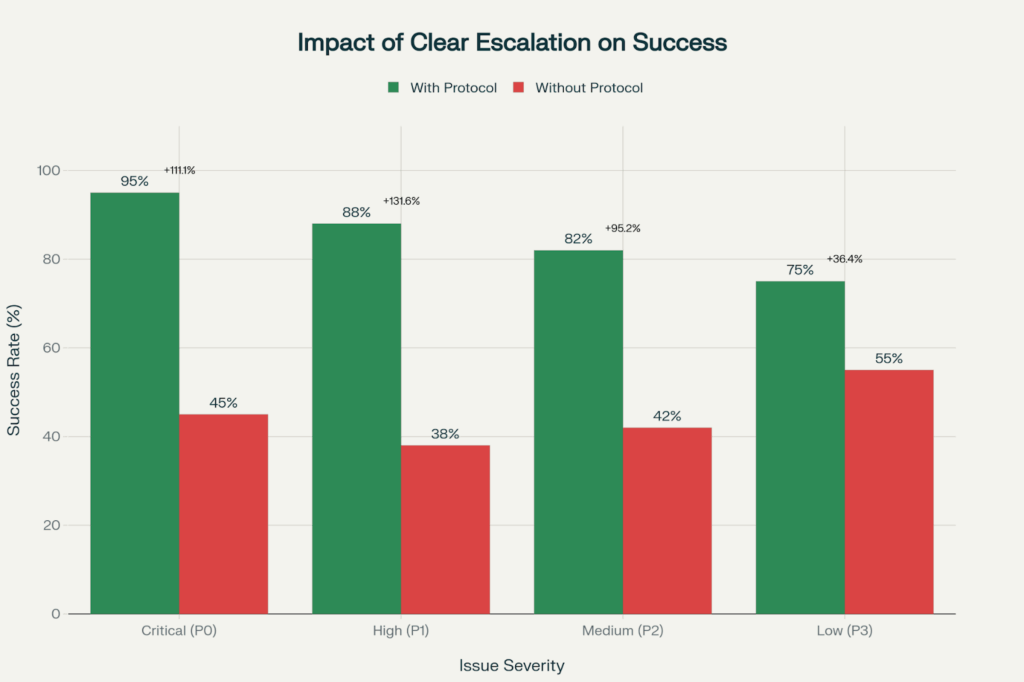
This dramatic contrast demonstrates solid escalation procedures that more than double success rates for critical issues, from 45% to 95% for P0 incidents
Define explicit severities with corresponding response time SLAs:
P0 – Critical:
P1 – High:
P2 – Medium:
P3 – Low:
Documents clear escalation paths to avoid confusion during incidents:
Weekday business hours escalation (India 9 AM-6 PM IST):
Weekday business hours escalation (US 9 AM-6 PM EST/PST):
Off-hours / Weekend escalation:
Contact information document maintained in LastPass, Confluence, and printed copies includes:
Format the escalation messages in a uniform way to provide the required information:
P0 Escalation Template:
text
🚨 P0 INCIDENT – IMMEDIATE RESPONSE REQUIRED 🚨
WHAT: [One sentence description – e.g., “Payment API returning 500 errors”]
IMPACT: [User impact – e.g., “All payment attempts failing since 14:23 IST”]
STARTED: [Timestamp in multiple timezones – “2:23 PM IST / 3:53 AM EST”]
CURRENT STATUS: [What’s happening now – e.g., “Error rate 100%, investigating”]
DIAGNOSTIC INFO:
– Error message: [paste key error]
– Affected systems: [list systems/services]
– Monitoring dashboard: [link]
– Initial investigation: [what you’ve tried]
INCIDENT CHANNEL: #incident-2025-10-28-payment-outage
INCIDENT DOC: [Confluence/Google Doc link for collaborative debugging]
@on-call-engineer @engineering-manager
P1/P2 Escalation Template:
text
⚠️ P1 INCIDENT – Requires Attention
WHAT: [Brief description]
IMPACT: [Which users/functionality affected]
STARTED: [When noticed]
SEVERITY: [Why P1 vs P0 or P2]
INVESTIGATION:
– Logs: [link]
– Dashboard: [link]
– Related tickets: [link]
– What we know: [summary]
– What we’ve tried: [steps taken]
NEXT STEPS: [What needs to happen]
OWNER: [Assigned person or “seeking owner”]
Thread discussion here: 🧵
Distribute your on-call rotations equitably across time zones:
Follow-the-sun model: Primary on-call alternates b/w India-based (covering IST business hours + evening) and US-based engineers (during EST/PST business hours). We never want to have a single person responsible for being on-call 24/7.
Duration of rotation A one-week rotation seems to offer a good compromise between disrupting knowledge flow and operator wear-down. Shorter rotations (daily) cause way too many handoffs; longer rotations (2+ weeks) cause burnout.
Compensation and recuperation: On-call engineers are given additional compensation (typically 10–20% of base salary, or per-incident bonus) as well as recuperation time following middle-of-the-night pages (arriving late the next day, or taking the following day off).
Exemptions and preferences: Engineers may temporarily opt out of on-call for significant life events (new baby, moving, family emergency). Monitor early-morning vs. late-evening preferences to best assign work.
Escalation to managers: after 3+ engineers in rotation don’t respond, engineering managers are paged rather than continuing to page down the list indefinitely. This suggests that either the notification system is sending too many false alarms or that the on-call pool should be increased.
And when you do have synchronous meetings, make them exceptionally productive to make up for the coordination overhead.
Weekly sprint planning (60-90 minutes):
Bi-weekly retrospectives (45-60 minutes):
Monthly architecture review (90 minutes):
Pre-meeting prep: Send supplemental agendas with background materials at least 24 hours in advance. No informed, distributed attendees without ‘prep time’ are able to contribute.
Record it all: Capture synchronous discussions with Loom, Zoom recordings, or meeting transcription services. One to two teammates who were unable to attend due to time zones can catch up asynchronously.
Participation: Have a facilitator actively encourage us to participate in the evening: Specifically ask quiet attendees (who usually contain non-native English speakers who might require more time to think of their answers). Create a Slack back-channel during meetings for side questions and comments.
Time-box and be ruthless: Begin and end on time to honour the people who juggled their schedules in order to attend. Take tangential discussions offline — in asynchronous channels.
Update decisions right away: Designate a member to keep decision logs, Confluence pages, or shared docs updated in meetings. Don’t depend on memory or meeting reconstruction.
Actionable items with owners: each and every meeting should end with clear next steps, owners, and deadlines tracked in project management tools. Vague promises dissipate across time zone divides.
The right tool stack for enabling async workflows is what makes success:
Communication:
Documentation and knowledge:
Project management:
Code and development:
Synchronous (when needed):
Critical tool requirements:
Monitor metrics that quantify the efficiency of distributed collaboration:
Quality Score for Handoff: Survey developers on a weekly basis: “Was the handoff from yesterday enough information to clear your shift?” Target 8+/10 average.
Async completion rate: Monitor the number of status updates, code reviews, and decisions that are done asynchronously vs. those that require synchronous meetings. Target 80%+ async.
Escalation response time: Track the elapsed time in minutes from incident creation to first response by severity. Target P0 <15min, P1 <60min.
Decision log coverage: How many significant decisions are logged in logs? Target 90%+.
Deep work hours: Developer self-reports of focus blocks: Anonymized information about how many focus blocks developers got in a week. Target 15-20 hours.
Meeting hours: Measure how much time a person spends in meetings each week. Target of less than 8 hours per week for individual contributors and 12 hours for managers.
Frequency of deployment: Track the number of deploys per week as a proxy for how collaboration-efficient your teams are. Better handoffs, async coordination should all improve the deployment velocity.
Time to resolution: Time between bug report and deployed fix, broken down by severity. Track trends over time.
Monitor these metrics quarterly and look for patterns and potential efficiencies of workflow improvement.
Pitfall #1: Relying on synchronous communication. When confronted with ambiguity or urgency, teams reflexively book meetings rather than experimenting with async options first. Solution: Require a 24-hour cooling-off period before holding meetings—most “urgent meetings” are unnecessary after a moment’s thought.
Pitfall #2: Uneven quality of handoffs. Under time constraints, developers abandon or speed through handoffs, compounding issues. Solution: Require handoff completion in your definition of done—work isn’t done until the handoff is documented.
Pitfall #3: What triggers escalation? In the absence of clear severity definitions, teams escalate too much (they wake people up for non-emergencies) and escalate too little (they let critical problems linger). Solution: Add concrete examples for each severity level–and review the escalation patterns monthly.
Pitfall #4: Decision log decay. Teams begin well, but after initial enthusiasm, momentum wanes, and they stop logging decisions. Solution: Make decision logging part of workflow automation – have template Confluence pages generated from JIRA tickets for architectural decisions.
Pitfall #5: The Hours Are Still Awkward. Making one side always work awkward hours leads to attrition. Fix: Use rotating sacrifice schedules, and pay a premium for work performed in the off-hours.
Pitfall #6: Tool sprawl. Having too many communication tools shatters information and cements the overhead. Fix: Perform annual tool audits, remove duplicates, and consolidate on the core stack.
Pitfall #7: Async resistance. There are those on our team who disagree with our async-first culture and insist on synchronous communication. Fix: Manager talent by example, celebrate async wins, and train on async comms skills.
Time zone cooperation mastery turns what at first seems like an obstacle into a strategic benefit. Coordination is tricky with 9.5–14 hours between India and the US, but the time difference can be used to run follow-the-sun that outputs a potential 20 hours of work daily if designed right – that’s 3.3 times the output of teams located at a single spot.
Success needs to be intentional systems-wise: working within the 4.5-7.5 hours of available intersecting time with flexible schedules, so on, so forth. is embraced to include async-first culture philosophy: eliminate meeting dependency, bring rigor in handoff document transaction to assure smooth transition from shift to shift, decision logs to ensure institutional memory, clear escalation route, leaving 3rd shift can sleep well,l and potentially no false alerts in the middle of the night, collaborative effectiveness managed by positive metric, not assumption.
The teams that successfully navigate distinct time zones understand that distributed collaboration isn’t about mimicking co-located work remotely but rather reengineering workflows to exploit the strengths of asynchronous communication and save precious synchronous moments for things that really require real-time interaction. As much as 80 percent of development work can be done asynchronously, meaning a substantial productivity boost is up for grabs if any teams are willing to buck meeting-centric culture norms.
With more companies adopting global talent and distributed work evolving from temporary arrangements into permanent setups, the playbook laid out in these pages will separate the highly effective distributed teams from the struggling ones. Time zones aren’t the enemy—bad systems are. With the right design, India-US and India-EU partnerships are not only doable but better than traditional co-located development.


